728x90

0.0. 요약
- 데이터 분석의 목적 : 비즈니스 행위의 방향을 결정하기 위함
- 데이터 웨어하우스 + 데이터 레이크 = 데이터 플랫폼
- 데이터 플랫폼의 3가지 문제점 : 규모, 다양성, 속도
- 데이터 웨어하우스 → 클라우드 데이터 플랫폼으로 전환
- 수집 , 스토리지 , 처리, 서비스 계층의 분리
- 실시간 스프림 데이터와 배치 데이터의 분리
- 서비스 계층의 3가지 역할
- 비즈니스 부서 : 보고서, 대시보드, 가공된 데이터
- 분석가 : SQL, (가공된) 정형 데이터
- 개발자 : 익숙한 프로그래밍 언어, 원시 데이터 조회
- 공부할 개념
- 수집 계층 : 카프카 커넥트 (플러그앤 플레이 수집 기능)
- 처리 계층 : 스파크(잘 알려진 파일 형식 파싱)
- 수집 계층
- 클라우드 데이터 웨어하우스
- 구글 : 빅쿼리
- AWS : 레드시프트
- 애저 : 시냅스
- 클라우드 데이터 웨어하우스
1.0. 들어가며
- 모든 비즈니스에는 분석이 필요함 비즈니스를 할 때에는 비즈니스 지표를 측정해야함 이 지표들을 기반으로 의사결정을 해야함 즉, 데이터를 분석하는 이유는 행위를 하는 방향을 파악하기 위함이다
- 데이터 웨어하우스의 시작 : 여러 소스 시스템들의 데이터를 한 군데로 모으는 저장소
- 클라우드 데이터 플랫폼의 간단한 정의
- 모든 유형의 데이터를
- 거의 무제한의 장소에서
- 비용 효율적인 클라우드 네이티브 방식으로
- 수집, 통합, 변환, 분석, 관리되는 데이터 플랫폼
- 기존 데이터 웨어하우스와 데이터 레이크 시스템이 가진 3V 문제
- 규모 Volumn
- 다양성 Variety
- 속도 Velocity
1.1. 데이터 웨어하우스에서 데이터 플랫폼으로의 이동과 관련된 동향들
- 기존 데이터 웨어하우스들의 문제점이 들어나고 있음
- SaaS 활용이 증가하면서 다양성과 종류가 크게 증가함
- 기존에는 정형 데이터만을 다루었으나, 최근에는 비정형 반정형 유형의 다양한 데이터가 생성되고 있음
- 실시간 스트리밍 데이터의 규모와 시간당 밀려 들어오는 데이터의 양의 증가 속도를 고려할 때, 일일 배치 업데이트 같은 방식으로 활용할 수 있는 수준을 훨씬 넘었다
- 애플리케이션 아키테처가 모놀리식에서 마이크로서비스 형태로 변경되고 있음
- 각 마이크로서비스로부터 메시지를 수집해야 하는 일이 핵심 과업 중 하나가 되었음
- 기존 데이터 웨어하우스 구조에서는 이러한 변화가 있을 때, 증가 속도에 맞춰서 대응하기도 어려웠고 그 비용을 감당하기 어려웠다
- 정형 데이터 분석만으로는 얻을 수 없는 원시 데이터에 직접 엑세스하는 경향이 늘어나고 있음
- 모델 관리 관점에서 상당한 도전 과제를 던져준다
- 왜? 원본 데이터 조회는 가장 기본 아닌가? 데이터 양이 많아서?
-> 데이터 웨어하우스와 데이터 레이브의 분리가 되어야해서
- 왜? 원본 데이터 조회는 가장 기본 아닌가? 데이터 양이 많아서?
- 모델 관리 관점에서 상당한 도전 과제를 던져준다
1.2. 데이터의 속도, 규모, 다양성이 증가하는 상황에서 데이터 웨어하우스의 한계
- 데이터 레이크와 데이터 웨어하우스를 결합한 형태로 데이터 플랫폼을 구축해야하는 필요성과 구축 방법을 이야기한다
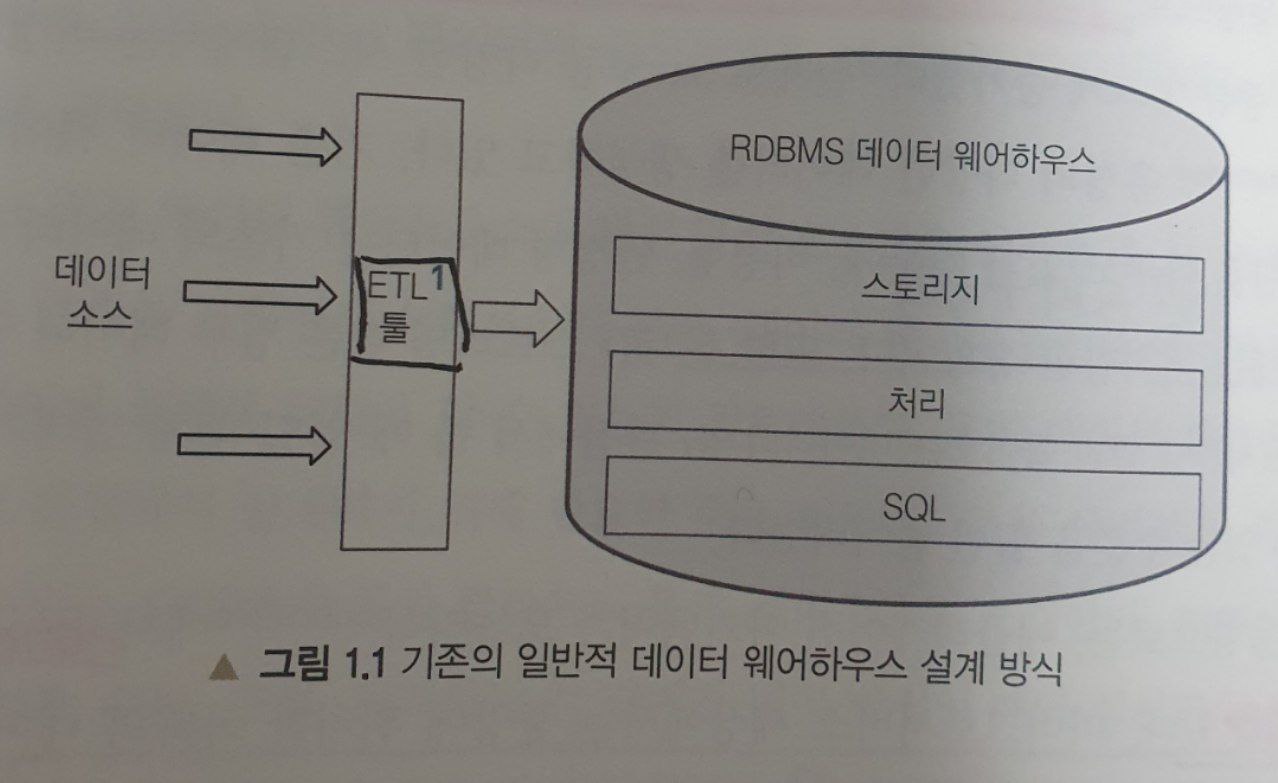
- 일반적인 데이터 웨어하우스 설계 방식
- 관계형 데이터베이스 기반의 데이터 웨어하우스에서 ETL 도구와 프로세스를 활용해서 데이터 웨어하우스의 테이블로 데이터를 수집하는 방식
- 단일 시스템상에 스토리지, 컴퓨팅(처리), SQL 서비스가 함께 구성돼 있음
- 처리 성능만 높이고자 할 때에도 스토리지 영역에 영향을 주게 된다
1.2.1. 데이터의 다양성
- 기존의 데이터 웨어하우스는 정형 데이터만 처리하도록 설계되어 있다
- 대부분의 데이터를 다른 관계형 데이터베이스 시스템에서 가져왔기 때문에 큰 문제가 없었다
- SaaS, SNS 등의 발전에 따라 분석할 대상이 다양해지고, 텍스트, 오디오, 비디오와 같은 비정형 데이터들도 분석 대상에 포함되었다
- SaaS 공급 업체들은 JSON 형식의 반정형 데이터 포멧을 사용하는 API를 제공한다
- JSON API 방식은 유연성이 높지만, 반정형 데이터이기 때문에 예고 없이 스키마의 변경이 동반된다
- 하지만 데이터 웨어하우스는 정형화된 데이터만 다루도록 설계돼 있고, SaaS 공급 업체들의 예고 없는 스키마 변경에 유연하게 대응할 수 있는 구조를 가지고 있지 않다
- ETL 툴이 효율적으로 처리할 수 있는 데이터 형식의 유형에 한계가 있다
- 기존의 데이터 웨어하우스를 활용해 데이터를 처리하려고 할 때, 반드시 웨어하우스에서 제공하는 SQL 엔진과 저장 프로시저 언어만을 사용해야하는 제약이 있다
- 이러한 구조적인 특성은 새로운 데이터 형식이나 새로운 처리 방식이 필요한 경우 한계점으로 작용한다
- SQL은 쿼리 언어로 상당히 우수하지만 테스팅, 추상화, 패키징, 공통 로직을 위한 라이브러리 등과 같은 기능의 제공이 부족하다
- 대부분의 ETL 툴은 처리한 데이터를 데이터 웨어하우스로 밀어 넣을 때 SQL을 주로 사용한다

1.2.2. 데이터 규모
기존 데이터 웨어하우스에서는 스토리지와 처리 영역이 결합돼 있어 확장성과 유연성에 큰 제약이 있다. 데이터 규모가 커지면서 더 큰 용량의 디스크, 메모리, CPU가 필요하다. 스토리지와 서버가 결합되어 있기 때문에 스토리지를 증설하기 위해서 필요하지 않은 컴퓨팅 자원을 구입해야 한다.

1.2.3. 데이터 속도
데이터가 시스템에 도착해서 처리되는 데까지 걸리는 시간, 즉 데이터 속도는 지금도 큰 문제이다. 그럼에도 실시간 분석 요구사항들이 계속 늘어나고 있다. 스트리밍 데이터를 처리해야 하는 필요성의 증가뿐만 아니라, 거의 준 실시간으로 분석해야하는 수요도 증가하고 있다.
- 기존의 데이터 웨어하우스는 배치 중심 처리 방식이었음
- 야간에
- 데이터를 스테이징 영역에 적재한 뒤
- 비즈니스 로직을 수행하고
- 그 결과를 Fact 테이블과 Dimension 테이블로 적재한다
- 배치로 새로운 데이터 처리를 마칠 때까지 기다려야 분석이 가능하다는 의미이다.
- 실시간 데이터에 대해서 처리를 하기 위해서는 기존 데이터 웨어하우스에서는 불가능했던 방식을 사용해야 한다
- 데이터를 실시간으로 처리하고
- 메모리에 데이터를 바로 올리고
- 이를 처리하는 높은 신뢰적을 제공해야 한다
1.2.4. 세 가지 V
- 인공지능과 머신러닝이 부상하면서 다양한 유형의 원시 소스 파일 데이터가 필요하다
- 이 모델들은 컴퓨팅 집약적이기 때문에 데이터 웨어하우스 환경에서 실행하려면 데이터 웨어하우스 시스템에 엄청난 성능 부담을 준다
- 기존의 방식에서는 몇 시간 또는 며칠이 걸리고, 기존 사용자들에게 영향을 준다
1.3. 데이터 레이크가 대안이 될 수 있을까?
- 데이터 레이크란
- 나중에 사용하기 위해 가공하지 않은 방대한 양의 데이터를 한 곳에 모아둔 스토리지 저장소
- 원천 데이터 소스로부터 나온 다양한 데이터 자산을 보관해 놓은 저장소들의 집합
- 원천 데이터 소스의 동일한 복사본기어나 거의 동일한 복사본의 형태로 저장되어 있음
- 특정 주제나 목적 중심이 아니며, 통합하지 않은 데이터 집합임
- 데이터 레이크의 등장 이유
- 기존 데이터 웨어하우스가 처리할 수 없는 데이터 형식의 증가
- 데이터 규모, 데이터 속도의 증가를 처리할 수 있는 방법이 절실히 필요한 상황
- 하둡의 등장
- 2006년 아파치 하둡
- 3V 문제의 해결
- 다양성
- 데이터 웨어하우스틑 schema on write
- 하둡은 schema on read
- 하둡은 어떤 형식의 파일도 시스템에 즉시 저장할 수 있으며, 나중에 처리된다는 것을 의미한다
- 정형 데이터만 저장할 수 있는 과거와 다르게 거의 모든 유형의 데이터를 처리할 수 있다
- 규모
- 하둡은 분산 서버, 분산 스토리지 구조이다
- 스토리지 비용을 절감할 수 있고, 많은 서버 간에 워크로드를 분산시킬 수 있다
- 속도
- 스트리밍이나 실시간 처리를 해야하는 경우, 하둡을 활용하면 스트리밍 데이터를 수집, 저장, 처리하기 용이하고 비용도 저렴하다
- Hive, MapReduce. Spark 같은 제품을 함께 활용해 약간의 코딩을 추가하면 실시간 처리도 추가할 수 있다
- 다양성
- 즉, 지난 시간동안 데이터 센터의 데이터 레이크에 대한 실질적인 표준이 되었다
- 하둡의 단점
- 매우 복잡한 시스템으로 유지보수하기 쉽지 않다. 시스템 운영을 위해서는 고도의 기술역량을 가진 엔지니어 팀이 필요하다
- 데이터를 활용하는 사람들에게 쉬운 시스템이 아니다. 비즈니스 사용자가 비정형 형태를 이해하고 활용하기에 쉬운 시스템은 아니다
- 개발자 입장에서 오픈형 툴 세트 사용이 매우 유연해서 각 컴포넌트의 결합이 약하다. 즉, 잘 사용하려면 많으 노력이 필요하다. SQL 외에도 추가 설치한 언어, 라이브러리, 유틸을 잘 알고 사용해야 한다.
- 스토리지와 컴퓨팅이 분리되어 있지 않다. 스토리지와 컴퓨팅을 동일한 하드웨어 상에 구성할 수 있지만 고정된 비율로 구성해야만 효과적이다. 이러한 구조가 유연성과 비용 관점에서 제약 사항으로 적용한다.
- 시스템을 확장하기 위해 하드웨어를 추가 및 변경하려면 몇 개월씩 걸린다. 하둡 클러스터 이용률이 높거나 낮은 상태로 지속되는 경우가 발생한다
1.4. 퍼블릭 클라우드의 활용
- 퍼블릭 클라우드의 특성으로 인해 하둡의 한계를 뛰어넘는 데이터 레이크 설계가 가능해졌다
- 온디맨드 스토리지
- 온디맨드 컴퓨팅 리소스 프로비저닝
- 사용량 기반 요금 지불 모델
- 클라우드 환경에 데이터 웨어하우스와 데이터 레이크를 구축하기 시작하면서 PaaS 를 제공하려는 시도가 많아졌다
- PaaS : 복잡합 인프라 환경 구축과 운영을 쉽게 사용할 수 있도록 도와주는 클라우드 컴퓨팅의 한 범주. 고객은 애플리케이션 개발과 운영에 더욱 집중할 수 있게 된다
- 클라우드를 통해서 하둡의 데이터 레이크 설계 한계를 뛰어넘을 수 있게 되었다
- 데이터 레이크와 데이터 웨어하우스가 결합된 형태의 솔루션들이 클라우드에 등장하면서, 기존의 온프레미스 환경 구축 기반보다 훨씬 뛰어난 성능을 갖게 되었다
- 클라우드의 도입으로 얻은 장점
- 탄력적 리소스 : 스토리지든 컴퓨팅이든, 선호하는 클라우드 제공업체로부터 필요한만큼의 리소스만 사용한다. 수요의 변화에 맞추어 자동 또는 요청 방식으로 리소스를 추가하고 축소할 수 있다
- 모듈화 : 클라우드 환경에서는 스토리지와 컴퓨팅이 분리된 형태로 제공된다. 둘 중 하나만 증설해야되는 경우 효율적인 투자를 할 수 있다
- 사용량에 따른 지불
- 자본 투자, 자본 예산, 자본 상각 방식 → 운영 비용 방식으로의 전환
- 관리형 서비스의 보편화 : 온프레미스 환경에서 데이터 시스템의 운영, 지원 및 업데이트를 위한 인적 자원을 필요로 한다. 반면 클라우드 환경에서는 이러한 부분들이 클라우드 공급 업체가 수행한다.
- 즉시 사용 가능
- 차세대 클라우드 전용 처리 프레임워크 : 클라우드 환경에서만 사용할 수 있는 데이터 처리 프레임워크가 있다
- 신규 기능 출시 속도 : 데이터 웨어하우스 제품들이 클라우드로 출시되면서 점차 PaaS로 출시된다. 신규 기능이 나오면 즉시 활용할 수 있다
- AWS EMR은 오픈 소스 툴을 사용해 데이터를 처리하는 클라우드 데이터 플랫폼이다. AWS의 관리형 서비스 중 하나며, AWS 상에서 하둡과 스파크를 활용할 수 있다. AWS EMR + AWS S3 스토리지를 사용한다.
1.5. 클라우드, 데이터 레이크, 데이터 웨어하우스 : 클라우드 데이터 플랫폼의 등장
- 다양성이 높아진 데이터들을 기존의 데이터 웨어하우스 안에서 비용 효과적으로 처리하는 방법을 찾기란 쉽지 않다
- 데이터의 규모와 속도가 계속적으로 증가하는 추세인데, 이를 비용 효과적으로 처리하려면 데이터 웨어하우스뿐만 아니라 데이터 레이크를 함께 조합해서 솔루션을 구성해야 한다
- 데이터 레이크를 고려할 때 주의할 점은 비용 사용자, 특히 비즈니스 사용자가 사용하기 편리한 형태로 구성되어야 한다는 점이다
- 데이터 웨어하우스의 역할 : 비즈니스 사용자에게 잘 정제된 데이터를 제공하는 지점 역할
- 데이터 레이크 : 데이터 과학자와 기타분석 시스템에서 데이터 레이크에 거의 정제되지 않은 채로 저장된 데이터를 직접 액세스해서 탐색하고 분석할 수 있는 환경을 제공하는 역할
- 성능이 중요한 분석 과업들에서 데이터 레이크 형태로 구성되는 경우가 많다.
- 비용 측면에서 데이터 레이크가 데이터 웨어하우스보다 우수하다.
- 데이터 웨어하우스 방식 : 배치 처리 방식이었다면
- 데이터 레이크 방식 : 스트리밍과 같은 새로운 방식의 데이터 처리가 가능해졌다
1.6. 클라우드 데이터 플랫폼의 빌링 블록 (building block)
- 데이터 플랫폼의 목적 : 분석에 활용될 수 있도록 어떤 유형의 데이터든 최대한 비용 효과적인 방식으로 데이터를 수집, 저장, 처리해서 활용할 수 있도록 제공하는 것
- 데이터 플랫폼은 계층간 늣느하게 결합돼 있는 형태의 아키텍처를 지향한다. 각 계층은 각각의 특징 역할을 담당하고, 잘 정의된 API를 통해서 각 계층 간 상호교류한다.

1.6.1. 수집 계층
- 수집 계층은 데이터를 데이터 플랫폼으로 가져오는 역할을 맞는다
- 다양한 데이터 소스 : 관계형 데이터베이스, NoSQL 데이터베이스, 파일 스토리지, 사내 API, 타사 API 등
- 이 계층에서는 어떤 경우에도 수집되는 데이터를 수정하거나 변환해서는 안된다
- 데이터 레이크는 처리되지 않은 원시 데이터를 보관함으로써, 데이터 계통 추적(lineage tracking) 및 재처리(preprocessing)할 수 있어야 한다
1.6.2. 스토리지 계층
- 데이터 소스로부터 데이터를 수집해오면 저장을 해야 한다
- 데이터 레이크 스토리지 시스템은 데이터의 수집 속도와 양을 언제든지 수용할 수 있도록 확장성과 비용이 중요하다
- 거의 모든 원시 형태의 데이터를 저장할 수 있어야 한다
- 데이터 레이크 사용자가 다양한 방법으로 데이터를 변환하거나 분석을 시도할 때 시스템적으로 언제든지 확장 가능해야 한다
- 기존 환경 : 데이터 센터 환경에서 스토리지를 확장하려면 대용량 디스크 어레이, 네트워크 연결 스토리지(NAS)를 사용했다. 이러한 엔터프라이즈급 솔루션은 비싸고 정해진 용량 단위로 거래해야하고, 더 많은 스토리지를 얻으려면 더 많은 기기를 함께 구매해야했다
- 클라우드 : 이러한 요소를 고려할 때, 클라우드 공급 업체의 최초 서비스 중 하나가 스토리지 서비스였다는 점은 놀랍지 않다.
- 모든 파일 형식을 저장할 수 있다는 특성은 데이터 레이크의 중요한 기반이다.
- csv, json과 같은 텍스트 파일, 이밎, 비디오와 같은 바이너리 파일 등
- NAS(Netword-Attached Storage)와 HDFS(하둡 DFS)는 클라우드 스토리지랑 다르다. 클라우드 스토리지는
- 클라우드 공급 업체의 완전 관리형 서비스다. 유지보수, 업그레이드 등에 대해 고민할 필요가 없다
- 탄력성이 좋다.
- 사용량에 따라서 비용을 지불한다
- 클라우드 스토리지와 직접적으로 연결된 컴퓨팅 리소스가 없다. 저장 공간을 위해서 컴퓨팅 자원을 구매하지 않아도 된다.
1.6.3. 처리 계층
- 원시 데이터를 직접 분석하는 방식으로 데이터 레이크를 설계할 수도 있다.
- 생상성이나 효율성 측면에서 데이터 레이크 구축 시, 좀 더 사용하기 쉽게 원시 데이터를 어느정도 미리 변환해두는 것이 일반적이다
- 데이터 베이스를 구축할 때에는 데이터베이스공급 업체에서 제공하는 SQL 엔진에 국한된다
- 제약 사항
- 추상화, 모듈화, 라이브러리화, 단위 테스트, 통합 테스트 수행이 불가하다
- 모든 데이터 처리가 RDBMS의 데이터베이스 엔진 내부에서 이루어져야 한다.
- 데이터 처리 작업에 사용할 수 있는 컴퓨팅 리소스의 한계는 해당 데이터베이스 서버가 제공하는 CPU, MEM, DISK의 크기에 달려있다.
- SQL의 이러한 제약 사항에도 불구하고, SQL은 데이터 레이크에서 데이터 분석용으로 널리 사용되며, 실제로 많은 데이터 서비스 구성 컴포넌트들이 SQL 인터페이스를 제공한다
- 극복
- 클라우드 컴퓨팅 리소스를 활용해 데이터 처리 프레임워크를 확장성 있게 구성해야 한다
- 제약 사항
- 아파치 스파크, 아파치 빔, 아파치 플링크
- 현대의 프로그래밍 언어를 사용해서
- 데이터 변환
- 유효성 검사
- 정제 작업(cleansing)을 흐름 수준으로 쉽게 개발할 수 있도록 지원한다
- 이 프레임워크를 통해 클라우드 스토리지로부터 데이터를 읽고, 더 작은 청크로 분할하고 (데이터 규모에 따라서 필요한 경우), 마지막으로 클라우드 컴퓨팅 리소스들을 사용해서 이 데이터 청크를 처리한다
- 데이터 레이크에서 데이터 처리 방식
- 수집 계층에서 수집된 데이터를 클라우드 스토리지에 저장하고, 처리 계층에서는 이 데이터를 읽어서 처리한 뒤, 결과를 클라우드 스토리지에 다시 저장한다
- 배치 모드 : 먼저 데이터가 스토리지에 저장된 다음 처리된다
- 스트림 : 스트리밍 모드에서는 데이터 수집 후 처리 계층으로 바로 전송된 뒤 저장된다
- 위와 같은 처리 방식은 배치 데이터에 더 적합하다. 클라우드 스토리지는 확장성이 뛰어나지만, 처리 속도가 그렇게 빠르지 않다.
- 처리 요구사항이 초 단위 이하가 되는 사례라면 주로 스트림 기반 데이터 처리로 해결한다.

1.6.4. 서비스 계층
- 서비스 계층의 목표 : 사용자나 다른 시스템에서 데이터를 활용할 수 있도록 준비하는 것
- 클라우드에서는 다양한 요구사항들을 단일 아키텍처 내에 구성할 수 있다.
- 비즈니스 부서의 사용자 : 셀프 서비스 방식, 그들이 원하는 다양한 보고서와 대시보드
- 애플리케이션에서 데이터 레이크의 데이터를 엑세스하게 하려면, 먼저 데이터 레이크의 데이터를 key/value 저장소나 문서 저장소에 적재하고, 애플리케이션이 그쪽을 바라보게 한다.
- 파워유저와 데이터 분석가 : SQL 쿼리를 바로 만들어서 직접 실행하고 몇 초 안에 즉각 응답받기를 원한다.
- SQL 엑세스 속도를 높이기 위해 데이터 레이크의 데이터를 클라우드 데이터 웨어하우스로 적재할 수 있다
- 데이터 과학자나 개발자 : 익숙한 프로그래밍 언어를 사용해서 새로운 데이터를 변환하고, 머신러닝 모델을 구축하고자 한다.
- 스파크, 빔, 플링크와 같은 프레임워크를 활용한다.
- 일부 클라우드 공급 업체는 주피터 노트북이나 아파치 제펠린과 같은 과리현 노트북 환경을 제공한다
- 비즈니스 부서의 사용자 : 셀프 서비스 방식, 그들이 원하는 다양한 보고서와 대시보드
1.7. 클라우드 데이터 플랫폼이 세 가지 V를 다루는 방법
1.7.1. 데이터 다양성
-
- 다양한 소스 시스템과 다양한 데이터 유형들을 수집할 수 있어야 한다
- 소스 시스템 지원이 필요하다면 플러그 앤 플레이 방식으로 적합한 애플리케이션을 추가하고 제거한다
- 카프카 커넥트, 아파치 나이파이 등과 같은 플러그앤 플레이수집 계층
- 스토리지 계층
- 클라우드 스토리지가 포괄적인 파일 시스템이기 때문에 JSON, CSV, 비디오, 오디오 데이터 등 어떤 데이터 형식이든 저장할 수 있다
- 클라우드 스토리지가 지원하는 데이터 유형에는 제약이 없으므로, 어떤 유형의 데이터도 쉽게 추가 가능하다
- 데이터 수용성
- 아파치 스파크, 아파치 빔과 같은 데이터 처리 프레임워크를 사용하면 SQL 프로그래밍 언어를 사용할 때의 제약점들을 극복할 수 있다
- SQL과 달리 스파크에서는 기존 라이브러리를 활용해서 이미 알려진 파일 형식을 쉽게 파싱해 처리할 수 있다
1.7.2. 데이터 규모
- 클라우드 스토리지는 자주 사용할 용도, 장기 보관 용도 등 사용 빈도와 제공 용량별로 다양한 스토리지 옵션이 존재한다
- 대량의 데이터를 클렌징하거나 검증할 때에는 컴퓨팅 용량이 많이 필요하지만 지속적으로 필요하지는 않다. 또 이러한 과정에서 저가 스토리지를 사용하면 비용을 효율적으로 절감할 수 있다
- 클라우드 스토리지는 원시 데이터를 저장하기 위해 가장 적은 비용이 드는 방법이다
- 비즈니스 사용자를 위해 처리된 데이터 관리 측면에서 실질적인 표준은 데이터 웨어하우스이다.
- 클라우드 데이터 웨어하우스
- 구글 : 빅쿼리
- 쿼리 실행과 연관된 리소스 사용량에 대해서만 요금을 지불하는 정책
- AWS : 리드시프트
- 애저 : 시냅스
- 구글 : 빅쿼리
- 클라우드 데이터 웨어하우스
1.7.3. 데이터 속도
- 수집 계층
- 최신 데이터 처리 프레임워크는 실시간 처리 기능을 안정적으로 제공하기 위해, 실시간으로 수집 계층에 빠르게 들어오는 데이터를 클라우드 스토리지 계층에 저장하지 않고, 처리 계층으로 바로 전송하는 방식으로 구성할 수 있다
- 스토리지 계층
- 클라우드 환경에서는 실시간 워크로드와 배치 워크로드를 굳이 공유하지 않아도 된다. 컴퓨팅 리소스를 탄력적으로 운영할 수 있기 때문이다.
- 처리 계층
- 처리 이후 결과를 저장하는 데이터를 목적에 맞게 다르게 보관할 수 있다
- 애플리케이션 사용 목적 : key/value 저장소
- 아카이브가 목적 : 클라우드 스토리지
- 리포팅이나 애드혹 목적 : 클라우드 웨어하우스
- 애드혹 : 즉시 또는 임시로 마련된 데이터. 특정 용도를 위해 임시로 특별하게 만든 SQL이나 분석 작업. 미리 준비해서 항상 동일한 출력 결과를 갖도록 만든 SQL 쿼리와 대조적이다.
- 처리 이후 결과를 저장하는 데이터를 목적에 맞게 다르게 보관할 수 있다
- 머신 러딩 모델을 돌리려면
- 대량의 데이터를 필요로 한다
- 정형화되고 큐레이션된 데이터 웨어하우스의 데이터도 사용하지만,
- 대부분 데이터 웨어하우스에 존재하지 않는 원시 소스 파일 데이터를 사용한다
- 데이터 웨어하우스에서 실행할 수 없는 굉장히 컴퓨팅 리소스를 많이 필요로 하는 기능이라, 실행 중인 동안 다른 사용자들의 업무 처리 성능에도 크게 영향을 준다
- 이러한 요구사항은 데이터 레이크를 사용할 수 있도록 제공이 가능해야 한다
1.7.4. 추가 V 두 가지
- 정확성 Veracity와 가치Value
- 가치 : 데이터 사용자가 필요할 때 언제든지 필요 데이터를 액세스해서 기대 결과를 출력한다
- 정확성
- 데이터 레이크의 장점
- 많은 양의 데이터를 사용자에게 제공하는 장점이 있지만
- 데이터 레이크의 단점
- 클렌징 상태, 구조화 수준 등 관리 관점에서 데이터 웨어하우스보다 관리 수준이 상대적으로 낮다
- 데이터 정확도를 높이기 위해 데이터 거버넌스를 강화해야하기도 하고 데이터 가치를 높이기 위해 더 많은 데이터를 수급해야할 필요성도 생긴다.
- 데이터 레이크의 장점
- 데이터 레이크가 제공하는 목적의 관점에서 정확성과 가치의 균형이 중요하다
- 원시 또는 일부 가공된 상태로 보관하는 저장소로도 쓰인다
- 웨어하우스용 데이터 세트를 만들어 내기 위한 소스 데이터로서도 쓰인다
- 예를 들면, 분석 → 모델링 → 모델 실행 → 결과 검증 → 결과를 데이터 웨어하우스에 저장
1.8. 공통 유스 케이스
- 데이터 플랫폼을 설계하거나 기획할 때, 다양한 유스케이스를 수집하고 이해하는 것이 중요하다
- 사용 활경에 대한 이해가 없이 진행하게 되면, 실질적인 비즈니스 가치를 제공하지 못하게 된다
- 유스케이스 1
- 고객 접점에서 발생하는 데이터를 모두 수집해서 고객 단일 뷰로 통합해서 관리한다
- 고객 경험 개선, 마케팅 부서의 개인화 서비스 개선, 가격 정책 유연화, 고객 이탈 방지 감소, 교차 판매개선
- 유스케이스 2
- 장비와 센서로부터 발생한 데이터를 활용
- 생산 현장에서 장비의 이상 증상 예측, 스키 경기에서 선수의 위치와 성정을 모니터링
- 유스케이스 3
- 머신러닝과 AI를 활용한 분석
- 데이터웨어하우스보다 데이터레이크가 훨씬 경제적
- 무제한의 원시 데이터를 비용 효과적으로 저장하는 공간
- 데이터레이크 = 데이터 과학자의 꿈을 실현하는 공간
728x90
'DEV > Data Platform' 카테고리의 다른 글
| 데이터 플랫폼 설계와 구축 | 2장 데이터 웨어하우스만이 아닌 데이터 플랫폼인 이유 (0) | 2024.03.31 |
|---|---|
| 데이터 플랫폼 설계와 구축 | 03. 빅3의 활용과 확대 | 수집, 저장, 처리, 메타데이터 계층 설계시 고려사항 (1) | 2023.11.06 |
| 데이터 플랫폼 설계와 구축 | 02. 데이터 웨어하우스만이 아닌 데이터 플랫폼인 이유 | 데이터 플랫폼에서의 데이터 수집,처리,엑세스 방식 (1) | 2023.11.04 |
| 데이터 플랫폼 설계와 구축 | 02. 데이터 웨어하우스만이 아닌 데이터 플랫폼인 이유 | 데이터 웨어하우스와 데이터 플랫폼의 차이 (1) | 2023.11.01 |
| 데이터 플랫폼 설계와 구축 | 01. 데이터 플랫폼 소개 | 하둡 이후 퍼블릭 클라우드의 활용 (1) | 2023.10.31 |