저는 회사에서 로그 모니터링 서비스를 만들고 있습니다.

위의 화면에서 검색 조건은 content:*Exception*으로 입력되어 있습니다. 수집 된 로그 중에서 Exception이 포함된 로그를 조회하는 모습을 보여줍니다. 지정한 키워드가 포함되었는지 확인할 때에는 java.lang.String#startsWith(java.lang.String)을 사용합니다. 물론 이렇게 수집된 모든 로그에 대해서 FULL-SCAN을 하면 검색 속도도 안나오고 CPU도 많이 사용할 수 있습니다. 더 큰 문제는 지정한 검색 시간 안에 로그가 N개 있으면 N개의 문자열에 대해서 모두 startsWith 연산을 수행한다는 점입니다. RDBMS를 사용하는 환경이라면 Connection Pool을 오랫동안 점유하게 되고, FileDB를 직접 만들어서 사용하는 저와 같은 경우에는 DISK IOPS가 치면서 자원을 낭비하게 됩니다. 가장 큰 문제는 이 트랜잭션을 수행할 때 자원의 과점유로 인해, 다른 사용자의 서비스 사용에 영향을 줄 수 있다는 점입니다.
물론 grok-parser 를 사용해서 로그를 구조화된 형태로 변경을 할 수 있다면, 문자열 FULL-SCAN을 사용하지 않고 인덱스를 사용해서 효율적으로 데이터를 빠른 시간 내에 조회할 수 있습니다. 하지만 아래와 같은 이유로 문자열 FULL-SCAN을 사용하는 기능을 개발하게 되었습니다.
1. 아직 자동화된 로그 파서 기능을 제공하지 못합니다. 예를 들어, 로그를 수집하는 에이전트 단계에서부터 '어떤 종류의 로그'인지 알 수 있다면 그 종류에 맞는 파서를 미리 정의해두고 자동으로 활성화되게 할 수 있습니다. 하지만 아직은 파서 기능의 초기 단계라서 grok-parser와 json-parser 두 가지만을 제공하고 있습니다.
2. 비정형 데이터를 파싱하기 위해서는 먼저 문제가 되는 로그의 포멧을 특정할 수 있어야 합니다. 가장 일반적으로는 Error 또는 Exception이라는 키워드가 포함되는 로그를 '인덱스 없이' 조회할 수 있는 기능이 있어야 합니다.
이런 상황에서 문자열 FULL-SCAN 기능을 제공하기 위해서, 서비스의 안정적인 가용성을 위해서, 두 가지 제약 조건을 고려했습니다.
검색 시간동안 수집된 데이터에 대해서
1. 최대 T시간 동안 데이터 문자열 매칭을 시도한다
2. 최대 N개의 데이터만 문자열 매칭을 시도한다
이 두 가지 방식의 차이에서 각각 '성능'과 '사용자 경험'을 의미할 수 있다는 점을 알게되었습니다.
디자인팀에서 만들어주신 시안을 가지고 좀 더 풀어보겠습니다.
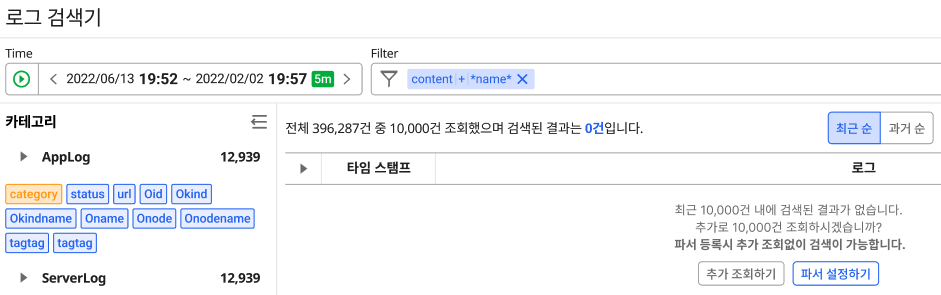
현재 데이터 조회 시간은 19시 52분 ~ 19시57분으로 5분입니다. 5분동안 396,287개의 로그가 수집이 되었습니다. 약 40만개의 로그 중에서 name이라는 키워드가 포함된 로그를 검색하고 싶습니다. 앞서 말씀드린 제약사항을 이유로 일정 갯수만큼 끊어서 조회하는 방식의 접근이 필요합니다. 위의 시안에서는 1만개씩 조회하고, 조회가 끝나면 그 다음 1만개를 조회할 수 있도록 설계된 방식입니다. '전체 396,287건 중 10,000건 조회했으며 검색된 결과는 0건'이라는 안내 문구를 통해서 '조회 시간 5분동안 수집된 로그에 대해서 첫 페이지(1만건)을 조회했다.' 라는 것을 알 수 있게됩니다.
그런데 만약 제약 조건 중 'N개의 데이터를 조회'하지 않고 'T시간 동안 데이터를 조회'하도록 사용자 동선을 설계한다면 아래와 같은 안내 문구를 보게 됩니다.
전체 396,287건 중 3,982건 조회했으며 검색된 결과는 0건입니다. (계속 조회하시겠습니까?)
전체 396,287건 중 12,342건 조회했으며 검색된 결과는 0건입니다. (계속 조회하시겠습니까?)
...
전체 396,287건 중 396,287건을 조회했으며 검색된 결과는 0건입니다. (검색이 종료되었습니다.)
이처럼 시간을 기준으로한 설계에는 다음과 같은 문제점을 가지고 있습니다.
1. 총 몇 번을 조회해야 전체 데이터를 모두 조회할 수 있는지 알 수 없음
2. 전체 현재 몇 번째 조회를 하고 있는지 알 수 없음
3. 앞으로 얼마나 더 '추가 조회하기' 버튼을 눌러야하는지 예측할 수 없음
물론 'N건의 데이터를 조회'하는 대신에 'T시간동안 데이터를 조회'를 해서 '추가 조회하기' 버튼을 누르는 횟수를 확실하게 줄일 수 있다면 시간을 기준으로 조회하는 방법이 더 나은 방법일 수 있습니다. 하지만 다양한 환경의 사용자가 존재하는 SaaS 서비스의 특성을 고려해서 일관되고, 예측 가능하고, 좀 더 사용이 불편할지라도 모든 사용자가 동일하게 인지할 수 있는 방식을 선택하기로 했습니다.
로그 모니터링 서비스에서 로그를 검색하는 기능이 불편한 것이 가장 큰 문제가 아닌가? 고민했습니다. 검색 속도를 최대한 빠르게 해서, 한 번이라도 클릭을 해야하는 불편함을 최소화해야하지 않느냐? 생각해봤습니다. 하지만 아래의 이유로 지금의 선택을 유지하기로 했습니다.
1. SaaS 서비스라는 특성을 고려해서 안정적으로 서비스를 제공하는 것이 가장 기본적이고 중요한 가치입니다. 사용자 A가 일으킨 헤비 트랜잭션으로 인해 사용자 B의 서비스가 영향을 받으면 안됩니다.
2. 문자열 매칭 검색을 하는 행위는, 인덱스를 걸기 위해, 문제가 있는 로그의 패턴을 파악할 때만 사용합니다. 로그의 패턴이 파악되면 파싱을 하고 인덱스를 걸 수 있고, 그 다음에는 인덱스를 사용해서 매우 빠른 속도로 검색할 수 있습니다.
3. On-premise 환경 또는 SaaS에서 대형 고객사를 위해 전용 인스턴스를 사용하는 상황이라면 각 환경에 맞는 최적화된 최대 검색 갯수를 지정할 수 있도록 확장성있게 개발되었습니다.
4. 파서 기능의 자동화를 통해서 사용자가 직접 파서를 걸어야하는 상황은 줄어들 예정입니다.
단순히 성능만을 생각해서 클릭 한 번으로 최대한 많은 데이터를 조회하는게 좋지 않나? 라는 생각을 깨보는 경험이었습니다.
'DEV > INSIGHT' 카테고리의 다른 글
| 소프트웨어 장인 정신 - 커뮤니케이션 1 (0) | 2024.03.14 |
|---|---|
| 모니터링 데이터에는 LLM를 어떻게 붙여야할까? (0) | 2024.01.02 |
| COUNT와 Pagination, 필요없을 수 있습니다 (0) | 2023.09.24 |
| 어떤 기능을 먼저 만들어야할까? (0) | 2023.09.20 |