
1. 들어가며
알파고와 이세돌의 경기가 있었던 날이 2016년 3월이니, 벌써 거의 8년 전의 일입니다. 작년 2023년에는 GPT-4가 세상에 나왔습니다. 1년마다 정말 큰 변화를 맞이하고 있습니다. 모니터링 데이터 속에서 하루 하루를 살아가다보니 LLM의 흐름을 모니터링 데이터의 관점에서 생각해보게 되었습니다. 텍스트 데이터만 입력으로 받는 LLM을 모니터링 데이터에 어떻게 적용할 수 있을까요?

2. Elastic은 어떻게 했을까?
2.1. Vector DB 조금만 알아보기
Elastic Search는 내부적으로 Vector DB를 사용합니다. Elastic Master Class에서는 “Lucene을 세계 최고의 Vector DB로 만들겠다”고 선언하기도 했습니다. 그러면 이 Vector DB는 무엇이고 Elastic은 이 Vector DB를 어떻게 활용하고 있을까요?
Vector DB는 데이터를 ‘숫자 형태의 표현(vector)’으로 저장하는 것을 말합니다. 데이터를 숫자 형태의 표현으로 변환하는 과정을 embedding이라고 부릅니다. 이미지, 텍스트, 센서 데이터 모두 vector로 표현될 수 있습니다. 구조화되지 않은 데이터와 일부분만 구조화된 데이터도 모두 저장과 조회의 대상이 된다는 특징이 있습니다. 전통적인 RDB에 데이터를 저장할 때에는 데이터의 어떤 부분을 Column을 지정할지 결정해야합니다. vector DB는 이 과정이 없이도 저장과 조회를 할 수 있다고 생각해보면 구조화되지 않은 데이터를 저장하고 조회한다는 점이 얼마나 특별한 것인지 알 수 있습니다.

이렇게 vector로 표현된 데이터를 조회할 때에는 “가장 가까운 이웃”이라는 개념을 활용해서 데이터를 조회하게 됩니다. kNN(최인접이웃 알고리즘)이라는 가장 간단한 머신러닝 알고리즘이 있습니다. ‘가까운 거리에 있는 값과 비슷한 성질을 가질 것이다’라는 가정하에 유클리디안 거리를 사용해서 데이터를 분류하는데 사용됩니다. 예를 들어 아래의 빨간 세모는 노란색 네모에 더 가까운 성질을 가질 것이라고 보는 접근법입니다.

주의할 점은 거리에 따라서 이웃이 달라질 수 있다는 점입니다.

vector DB의 유사도 검색의 장점은 “정확하게 매칭되지 않은 대상이라도 검색할 수 있다”라는 장점이 있습니다. 그리고 단계적으로 검색을 수행할 수도 있다는 장점이 있습니다. 위의 사진에서라면 “일단 거리 10 안에서 가장 가까운 이웃을 찾고, 그 다음에 거리 1안에서 가장 가까운 이웃을 찾아.”와 같이 접근할 수 있습니다. LLM에게 제공하는 Prompt에 “Let’s think step by step”을 추가하는 것만으로도 문제를 풀기도 하는 특성을 유사도 검색의 특징이라고 이해 볼 수 있습니다. LLM에서는 ‘생각의 사슬 Chain Of Thought’이라고 표현되는 특징이기도 합니다.
여기서 기억할 점은 정확한 검색이 아니라 확률 기반으로 추정의 결과물을 조회한다는 것입니다. LLM이 정말 추천을 잘할까?라고 물어본다면 “더 정확한 추천을 해줄 수 있다”보다는 “추천해줄 수 있는 범위가 무제한에 가깝다”라고 이해하는 것이 더 올바른 방향입니다.
2.2. Elastic가 사용한 방법
Elastic Master Class에 참석해서 들은 이야기 중 가장 강렬하게 머릿속에 남은 것은 “ELASITC에서는 사내 데이터 기반으로 1차 검색하고 그 결과를 제한된 LLM의 입력으로 넣는 방식을 사용한다” 였습니다. 이러한 접근 방법은 아래의 순서로 구체화되어 사용장들에게 제공되고 있습니다.
- 사용자 입력을 받는다
- vector 검색 기능 사용해서 가장 유사한 사용자가 찾는 것과 가장 유사한 docs를 내부적으로 찾는다
- 2번에서 찾은 docs의 링크를 gpt에게 전달하면서 아래의 내용을 프롬프트에 추가한다 "answer this question using only this document "
- 2번에서 찾은 Docs의 링크, 3번의 프롬프트, 사용자의 질문을 함께 전달한다
2.3. Elastic은 왜 이러한 방법을 적용했을까
Elastic은 검색을 잘합니다. 크게 2가지 방식의 검색을 모두 사용합니다.
- 전통적인 키워드 및 텍스트 기반 검색(BM25)을 지원
- 정확한 일치 및 근사 kNN(k-Nearest Neighbor) 검색 기능
BM25과 kNN를 모두 활용해서 높은 정밀도의 결과를 제공할 수 있다는 장점에 서비스와 관련된 Docs가 방대하게 존재한다는 점을 엮어서 수준 높은 사용자 경험을 제공한 것으로 보입니다.
“훌륭한 검색 성능 + ChatGPT의 자연어 이해 능력 = 타의 추종을 불허하는 사용자 경험”
이라고 할 수 있겠습니다.
2.4. Elastic의 방법은 어떻게 동작할 수 있을까
Elastic에서 사용한 Docs를 검색해서 제공하는 방법이 아니라면
- 질의 자체를 embedding해서 vector DB에서 조회하거나
- 이렇게 조회된 결과를 그대로 혹은 텍스트로 변환해서 LLM의 Prompt로 다시 질문
하는 방법이 있습니다.
그런데 이러한 접근법에서 가장 어려운 부분은 “언어 모델과 수치 시계열 데이터 기저에 있는 패턴이나 semantics를 연결할 브리지”를 찾는 것입니다.
시계열 데이터와 언어 모델 사이에서 연관 관계를 어떻게 찾고 LLM에게 제공할 것인가?”의 문제를 Elastic은 관련된 Docs를 제공하는 방향으로 푼 것입니다.
이 부분은 책 ‘AI 전쟁’을 쓰신 네이버 AI 수장 하정우님께 콜드메시지를 보내서 답변 받았던 내용을 참고해서 작성했습니다.
하정우님 다시 한 번 귀한 시간 내어주셔서 감사드립니다. 보내주신 말씀을 여러번 되짚어보니 Elastic이 접근한 방법에 대해서 이해할 수 있었습니다.
3. 다른 접근 방법은 없을까?
3.1. 꿈같은 이야기 먼저
제가 생각한 방법을 말씀드리기 전에 꿈같은 이야기 먼저 해보겠습니다. 모니터링에서 중요한 RCA(Root Cause Analysis)에 대해서 리서치를 해보다가 발견한 내용들입니다.
글로벌 경쟁사(Elastic, Datadog etc)가 Anomaly detection 기반으로 RCA를 제공합니다. 이 중에서 글로벌 1위 Datadog은 APM을 사용해야만 RCA를 제공합니다. (APM --> Anomaly detection --> RCA)의 형태로 데이터를 조회하는 방향성입니다.
만약 Anomaly detection 만을 위한 기능을 개발하는 것이 아니라 시계열 데이터에 대해서 LLM이 가능해지고 LLM의 확률 기반 추정 모델에 따라서 Anomaly detection이 가능해진다면 다변량 분석이 가능해집니다. 대부분의 시계열 분석은 단변량 데이터에 중점을 둔 것과 달리 다양한 지표를 종합적으로 분석할 수 있게 되는 것입니다. LLM의 추천이 더 넓은 범위에 대해서 추천을 할 수 있는 것과 비슷하다고 느껴집니다.
정말로 시계열 데이터에 대한 LLM의 범용성이 확보된다면 Browser, Application, Server, Database, Network까지 End To End monitoring 전체에 RCA를 적용하고 글로벌 시장에서 대한민국 SaaS 모니터링이 차별성을 가질 수 있을 것 같습니다.
3.2. 다시 현실로 돌아와서
모니터링 데이터 중에서 중요한 정보는 Trace, Metric, Log 입니다. 이 3가지를 합쳐서 Observability라고 부르기도 합니다.
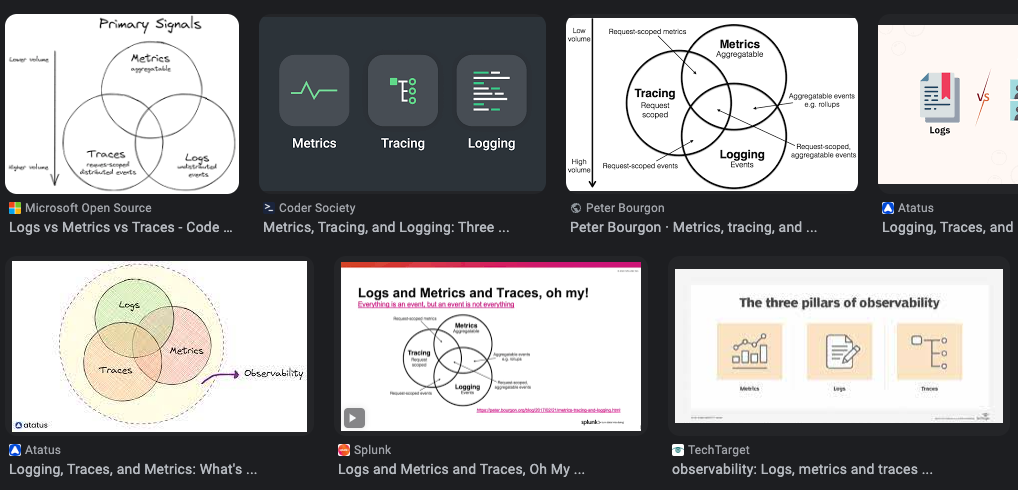
그래서 사용자의 로그 / 주요 메트릭 / IT 서비스 운영자들의 노하우를 LLM에게 학습시키는 방법에 대해서 고민해봤습니다.
3.2.1. 로그
로그는 원래 텍스트 데이터입니다. 그래서 LLM의 propmt로 그대로 입력될 수 있습니다. 하지만 로그 중에서는 불필요한 로그도 정말 많습니다. 그래서 “주문 서버에서 발생한 로그”, “WARNING 이상의 레벨을 가진 로그”, “특정 시간 구간에 포함된 로그”와 같은 형태로 유의미한 로그의 범위를 좁혀서 LLM에게 제공할 수 있겠습니다.
3.2.2. Trace
Trace도 원래 텍스트 데이터입니다. 가장 기본적으로는 Trace는 정상인지 에러인지와 응답 시간을 기준으로 중요한 트레이스를 찾을 수 있겠습니다. 여기서 한 번 더 나아가면, Transaction Id 또는 Multi Transaction Id를 사용해서 관련된 정보를 함께 제공할 수 있으면 유의미한 결과를 얻을 확률이 높아집니다. 한 번 더 나아가서 히트맵 가로/세로 패턴이 있는 경우 함께 LLM의 prompt로 제공될 수 있습니다. 가로줄 패턴이 있는 경우 특정 응답 시간에 요청이 끊어진 경우이기 때문에 timeout의 가능성이 있고, 세로줄 패턴이 있는 경우 특정 객체에 대한 lock이 순간적으로 풀리거나 모종의 이유로 모든 트랜잭션이 한 번에 종료된 경우입니다.
3.2.3. Metric
Metric에 대해서는 사실 제일 핵심적이고 범용적인 접근 방법인데, 아직 많이 리서치를 해보지는 못했습니다. 그래도 생각의 시발점이 될 수 있는 논문과 코드를 하나 남깁니다.
- https://github.com/ngruver/llmtime
- https://paperswithcode.com/paper/large-language-models-are-zero-shot-time-1
3.2.4 Know-How
Elastic 처럼 Docs가 많지는 않아도, 운영 담당자들이 각자 가지고 있는 노하우가 문서로 정리되고 이를 참조할 수 있으면 훨씬 더 유의미하고 관련도 높은 결과가 나오지 않을까 싶습니다.
3.2.5. User Behavior
사용자 행위에서 주로 READ는 관심 밖의 대상이 됩니다. 모니터링 서비스에서 메트릭을 조회하는 행위는 매우 많이 일어나서 메트릭 조회 행위를 기록으로 남기면 UPDATE, DELETE와 같은 행위의 기록을 찾기 어렵게 됩니다.
그런데 만약 어떤 사용자가 어떤 메트릭을 얼마나 많이 봤는지를 통계를 내고, 서비스 전체적으로 이 통계가 만들어진다면 “주로 이런 지표를 많이 조회하셨어요”, “다른 사용자는 이런 지표를 함께 확인해요”와 같은 추천 기능을 제공할 수 있을 것 같습니다. 또는 자신이 주로 보는 지표를 자동으로 골라서 대시보드로 만들어주거나, “통계적으로 볼 때 가장 관련이 있는 지표”라는 의미로 prompt에 제공될수 있습니다.
4. Don't reinvent the wheel.
밑에서 언급할 2가지가 책 ‘AI 전쟁’을 읽고 배운 2가지 중 가장 유익했습니다. 이미 만들어진 LLM을 텍스트가 아닌 다른 도메인에 적용하려고 할 때, 반드시 알고 시작해야하는 개념으로 생각됩니다.
4.1. 이미 문맥을 잘 이해한다, Transformer
트랜스포머는 2017년에 구글에서 발표한 인공신경망 모델입니다. 기존에 구글에서 번역을 할 때에는 LSTM을 사용했습니다. LSTM 모델은 문장을 단어의 순서에 맞춰서 입력해야합니다. 그래서 서로 멀리 떨어진 단어 사이의 연관성을 계산하는데 어려움이 있습니다. 반드시 순서대로 입력해야하다보니 병렬 연산에 어려움이 있었습니다. 그런데 트랜스포머는 순서대로 넣을 필요 없이 위치정보만 주면 attention 연산만으로 인코딩(글 내용 이해)도 되고 디코딩(글쓰기)도 된다는 것을 보여주었습니다. 병렬 연산에서 데이터의 순서를 보장하지 않아도 된다는 점은 방법론적인 관점에서 새로운 차원을 열어주었다고 평가됩니다.
4.2. 전용 모델을 만들 필요는 없다, Foundation
2021년 8월, 하나의 모델을 제대로 학습시키면 각 기능마다 별개의 모델을 사용하는 것보다 더 좋은 효과가 있다는 것이 발견됩니다. 이 이후로는 범용 인식 모델을 만들기 위해서 사전학습을 하고, 실제 적용할 문제의 데이터에 추가적인 파인튜닝을 하는 형태가 본격적으로 시작되었습니다.
GPT-3로 넘어오면서 거대 인공지능을 넘어 초거대인공지능으로 불리기 시작했습니다. GPT-3 이전에는 인공신경망의 노드가 많아야 1억개였는데 GPT-3는 1700억개의 노드를 사용해서 학습되었습니다. 너무 많이 차이나는 접근 방식을 구분하기 위해서 초거대인공지능이라고 명명되고 있습니다. 이러한 GPT-3부터는 파운데이션 모델에 대한 학습이 잘 되어 있어서, 각 전문 분야에 적응하기 위한 파인큐닝에 대한 노력이 이전 대비 1/100 정도의 수준으로 줄었습니다.
5. LLM에 대한 가벼운 생각들
5.1. 동영상 데이터도 학습할 수 있을까
비디오 데이터는 가로 세로 해상도, RGB 그리고 시간축까지 있습니다. 그래서 훨씬 더 많은 컴퓨팅 자원이 필요합니다. 이미 비디오 데이터를 기반으로 AI가 제공하는 기능들이 많이 있습니다만, 그래도 세상에 없던 동영상을 생성해주는 서비스가 아직 없는 것이 이 때문입니다. 아래와 같은 animate를 만들어주는 서비스는 벌써 있지만, “어떤 남자가 산 속을 올라가면서 촬영하는 영상을 만들어 줘”와 같은 프롬프트는 아직 동작하지 않습니다.
텍스트 데이터 → 이미지 데이터 → 시계열 데이터 → 동영상 데이터의 순서대로 발전의 흐름이 연결될 것이라고 생각합니다.
5.2. 텍스트만을 활용하는 인공지능이 너무 제한적으로 느껴진다면
인기 있는 매장의 경우, 매장에게 남겨지는 온라인 댓글들을 모두 확인하기가 어렵습니다. 인간이 이를 모두 확인하기에는 불가능에 가깝습니다. 이럴 때에 인공지능이 댓글을 빠르게 읽어서 3줄 요약을 해주는 기능이 네이버의 하이퍼클로바에 있습니다.
현대백화점에서는 마케팅팀에서 카피라이팅 문구의 초안을 작성하고 최종 결정까지 2주 정도가 걸렸다고 합니다. 이러한 상황에서 하이퍼클로바가 마케팅 문구 1만개를 학습하고 난 뒤에 소요시간이 2주에서 3시간으로 줄었다고 합니다. 더 고무적인 것은 관련 인원의 역할이나 일자리가 줄어들지 않고, 각 지점 / 매장 / 상품 별로 더 최적화된 카피라이팅을 제공할 수 있게 되었다고 합니다.
규모의 경제 속에서 태어난 LLM이다보니 지금까지 보지못했던 규모의 상황에서 도움을 처음으로 받게되는 상황이 발견되는 것 같습니다.
6. 마치며
LLM에 대해서 하나도 모르고 관심도 없던 제가 이렇게나마 이해하고 아이디어를 생각해볼 수 있도록 도와준 책 AI 전쟁과 그 저자 하정우, 한상기님께 감사의 말씀을 드립니다.
긴 글 읽어주셔서 감사합니다.
7. Reference


'DEV > INSIGHT' 카테고리의 다른 글
| 소프트웨어 장인 정신 - 커뮤니케이션 1 (0) | 2024.03.14 |
|---|---|
| COUNT와 Pagination, 필요없을 수 있습니다 (0) | 2023.09.24 |
| 어떤 기능을 먼저 만들어야할까? (0) | 2023.09.20 |
| 성능과 사용자 경험의 사이에서 (1) | 2023.09.20 |